 慧联谷
慧联谷来源 | 机器之心编译,智车科技(IT_Technology)整编
作者 | Piotr Mirowski等
当前的无人驾驶汽车高度依赖于精确的地图进行导航,尽管各家科技公司已经构建了接近完美的 3D 地图,但这种方式仍然存在一些弊端(巨大的容量、需要不断更新等)。近日,DeepMind 提出了一种端到端深度强化学习寻路方法,其训练的神经网络可以帮助汽车在没有地图的情况下正确前往目的地,这一研究或许可以帮助自动驾驶汽车技术向前迈进一大步。后台回复:无地图导航,可获得PDF版论文。
位置,是人们感知时空的能力。在古代,人们通过观察日影和星图,知晓了天圆地方和四季轮转,通过观察日晷,我们知晓了时间的变化,借助指南针,我们的祖先更是开启了大航海的时代。水电,云服务,卫星定位技术……的发明更是让人们的生活变得更加的便捷和美好。
随着社会的不断发展,人类社会的不断进步,特别是无人驾驶,车联网技术的日益发展,人们对于位置的精准度的要求达到了前所未有的高度。
而要到达精准的位置,离不开的就是导航。导航的实现离不开地图,当前的无人驾驶汽车高度依赖于精确的地图进行导航。
接下来,先想一个问题。小时候,你是如何熟悉周围环境路线的?例如怎么去朋友家、去学校或者去杂货铺?可能没有地图,只是简单地记住街道的外观、沿路的变向。随着在附近街区的探索逐渐增多,你变得更加自信,开始学习新的、更复杂的路。有时你可能会迷路,但是在路标或者太阳(指南针)的帮助下你可以重新找到正确的路。
导航是一项重要的认知任务,帮助人类和动物在没有地图的情况下穿过复杂世界中长长的路途。此类长距离导航可同时支持自我定位(「我在这里」)和目标表征(「我要去那儿」)。目前尽管各家科技公司已经构建了接近完美的 3D 地图,但这种方式仍然存在一些弊端(巨大的容量、需要不断更新等)。近日,DeepMind 提出了一种端到端深度强化学习寻路方法,其训练的神经网络可以帮助汽车在没有地图的情况下正确前往目的地,这一研究或许可以帮助自动驾驶汽车技术向前迈进一大步。
在论文 Learning to Navigate in Cities Without a Map 中,DeepMind 展示了一种交互式导航环境,该环境使用来自谷歌街景的第一人称视角图像,并游戏化该环境来训练 AI。尽管谷歌街景图像已经很标准了,但是人脸和汽车牌照比较模糊、无法辨认。DeepMind 构建了一个基于神经网络的人工智能体,可使用视觉信息(来自谷歌街景图像的像素)学会在多个城市之间导航。注意该研究是关于通常意义上的导航,并非驾驶。DeepMind 未使用交通信息,也没有尝试建模车辆控制。

在没有环境地图的情况下,DeepMind 智能体在视觉多样化环境中导航。
当智能体到达目标地点时会得到奖励(目标地点是指定的,如经纬度坐标),就像一个没有地图、带着大量货物的快递员。随着时间的推移,该人工智能体学会用这种方式穿越整个城市。DeepMind 还展示了其智能体可在多个城市中学习执行该任务,然后稳定地泛化至新的城市。

能体在巴黎训练时的定格动画。图像右上方是城市地图,显示目的地(红色)和智能体位置和视野(绿色)。注意该智能体无法看到地图,只能看到目的地的经纬度坐标。
不通过地图构建来学习导航
DeepMind 背离了传统的依赖于地图绘制和探索的方法(例如制图员给自己定位同时绘制地图)。相反,他们的方法是让系统像人类一样导航,不需要地图、GPS 定位或其它帮助,只需要使用视觉观测。他们构建了神经网络智能体,它以对环境的视觉观测图像为输入,并预测自己的下一个动作。他们使用了深度强化学习来端对端地训练智能体,这和最近的两项研究 LEARNING TO NAVIGATE IN COMPLEX ENVIRONMENTS 以及REINFORCEMENT LEARNING WITH UNSUPERVISED AUXILIARY TASKS 相似。但和这些研究所不同的是,他们没有使用小规模的虚拟环境,而使用了城市规模的真实世界数据,包括伦敦、巴黎和纽约中复杂的交汇道路、人行道、隧道以及各种拓扑结构。此外,他们的方法支持特定城市的学习和优化,以及通用的可迁移的导航行为。
模块化的神经网络架构,可迁移至新城市的导航
智能体的神经网络由三部分构成:(1)可处理图像和提取视觉特征的卷积神经网络;(2)地区特定的循环神经网络,可记忆环境,以及学习当前位置和目标位置的表征;(3)区域不变(locale-invariant)的循环网络,可以生成对智能体动作的导航策略。地区特定的模块被设计成可替换的,并且对于其导航的城市是唯一的,而视觉模块和策略模块则是区域不变的。
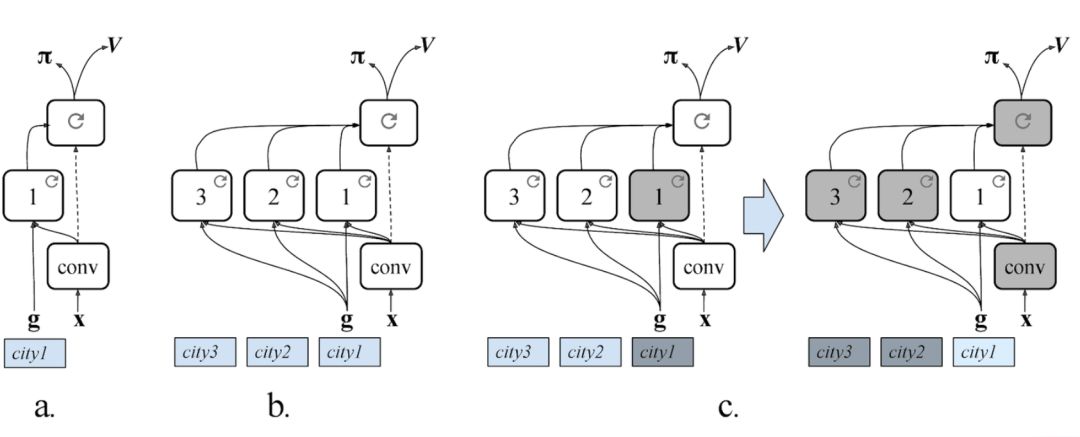
(a)CityNav 架构的对比;(b)MultiCityNav 架构,为每个城市提供地区特定的路径;(c)训练过程和将智能体适应到新城市的迁移过程。
正如谷歌街景中的界面一样,智能体可以在其位置旋转或走向下一个全景图。但和谷歌地图以及街景环境不同的是,智能体没有小箭头提示、局域或全局地图,也没有著名的 Pegman(学习区分公路和人行道)。智能体的目的地可能位于现实世界的数公里之外,它需要逐步利用数百个全景图才能到达目的地。
DeepMind 表示其方法提供了一种将知识迁移至新城市的机制。当智能体访问新城市时,人类当然希望它学习一系列新地标,但是没必要重新学习视觉表征或行为(如沿街道推进或在路口转弯)。因此,DeepMind 使用 MultiCity 架构,首先在多个城市中进行训练,然后冻结策略网络、视觉卷积网络和多个新城市特定路径。该方法使智能体在不遗忘之前所学知识的前提下获取新知识,与 Progressive Neural Networks 中的架构类似。
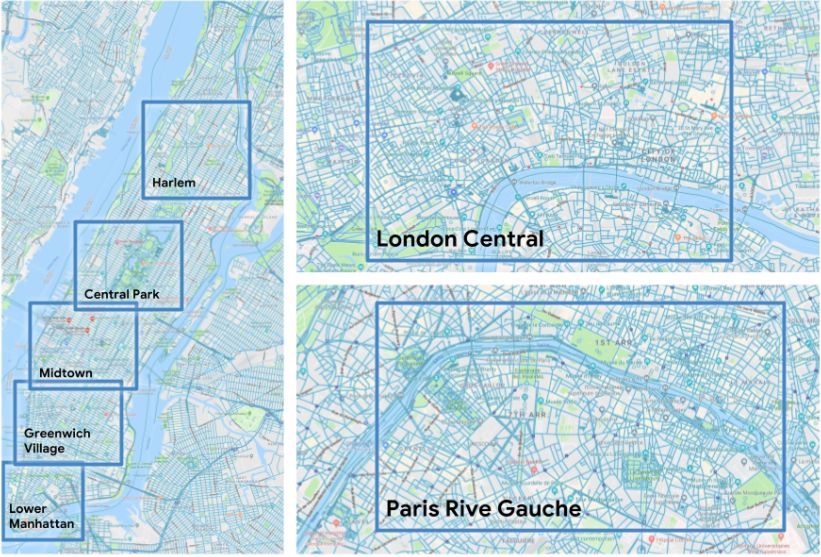
该研究中使用的曼哈顿五个区域地图
导航是人工智能研究和发展中的基础研究,尝试在人工智能体中复现人类导航也可以帮助科学家理解其生物性基础。
论文链接:https://arxiv.org/abs/1804.00168




评论前必须登录!
注册